


詳細(xì)信息
當(dāng)前位置:
首頁>
詳細(xì)信息
【網(wǎng)站百科】搜索引擎的工作原理
專欄:行業(yè)資訊
發(fā)布日期:2020-03-16
閱讀量:2760
作者:
SEO指根據(jù)一定策略、運(yùn)用特定計(jì)算機(jī)程序從互聯(lián)網(wǎng)上搜集信息,在對(duì)信息進(jìn)行組織和處理后,為用戶提供檢索服務(wù),將用戶檢索相關(guān)的信息展示給用戶的系統(tǒng)。
又可理解為通過自然搜索結(jié)果獲得網(wǎng)站流量的技術(shù)和過程,在了解搜索引擎自然排名機(jī)制的基礎(chǔ)上,對(duì)網(wǎng)站進(jìn)行內(nèi)外調(diào)整優(yōu)化,改進(jìn)網(wǎng)站在搜索引擎中的關(guān)鍵詞自然排名,從而獲取更多流量。它是英文Search Engine Optimization的縮寫,譯為“搜索引擎優(yōu)化”。

搜索引擎分類
介紹主流的三種,
1.目錄索引Yahoo、新浪
2.元搜索引擎Dogpile搜星搜索
3.全文索引百度、谷歌。
搜索引擎工作原理
爬行和抓取,搜索引擎用來爬行和訪問頁面的程序被稱為蜘蛛,也稱網(wǎng)絡(luò)爬蟲。
各主流搜索引擎蜘蛛的名稱:

百度:Baiduspider、Baiduspider-mobile(抓取wap)、Baiduspider-image(抓取圖片)、Baiduspider-video(抓取視頻)、Baiduspider-news(抓取新聞)。
谷歌:Googlebot
雅虎:“Yahoo! Slurp China”或者Yahoo!
360蜘蛛:360Spider,它是一個(gè)很“勤奮抓爬”的蜘蛛
微軟MSN: msnbot、網(wǎng)易有道:Roundabout、宜sou蜘蛛:EasouSpider
搜索引擎收錄流程
1.抓取:抓蟲通過百度、谷歌等搜索引擎進(jìn)行首頁、欄目頁、內(nèi)容等抓取,在互聯(lián)網(wǎng)中發(fā)現(xiàn)、搜集網(wǎng)頁信息,不過諸如js、Flash、inframe框架是不利于蜘蛛抓取的。
2.過濾:過濾不符合網(wǎng)站的相關(guān)內(nèi)容,將那些內(nèi)容雜亂無章、難易排序、采集的內(nèi)容沒有價(jià)值,不符合用戶的需求的內(nèi)容過濾掉,好的資源都放在數(shù)據(jù)庫中。
3.存儲(chǔ):對(duì)信息進(jìn)行有質(zhì)量的提取和組織建立索引庫
4.排序:當(dāng)用戶在搜索欄中輸入關(guān)鍵詞或目標(biāo)詞組后,搜索引擎能快速調(diào)用索引庫(數(shù)據(jù)庫)信息,搜索引擎通過一系列復(fù)雜的算法對(duì)即將呈現(xiàn)的結(jié)果進(jìn)行復(fù)雜的分析計(jì)算,排列出先后名次,呈現(xiàn)在用戶面前,方便用戶查詢預(yù)覽。

排名的先后當(dāng)然取決于用戶和搜索引擎的認(rèn)可程度!我們平時(shí)看到的搜索界面,實(shí)際上只是搜索引擎系統(tǒng)的一個(gè)檢索界面,當(dāng)你輸入關(guān)鍵詞查詢時(shí),搜索引擎會(huì)從龐大的數(shù)據(jù)庫中找到符合該關(guān)鍵詞的所有相關(guān)網(wǎng)頁的索引,并按一定的排名規(guī)則呈現(xiàn)給用戶。不同的搜索引擎排名不盡相同。
蜘蛛抓取策略
1.深度優(yōu)先
什么是深度優(yōu)先?簡單的說,就是搜索引擎蜘蛛在一個(gè)頁面發(fā)現(xiàn)一個(gè)連接然后順著這個(gè)連接爬下去,然后在下一個(gè)頁面又發(fā)現(xiàn)一個(gè)連接,然后就又爬下去并且全部抓取,這就是深度優(yōu)先抓取策略。
假如不是很理解,不妨理解為某個(gè)神秘的文件夾,打開打開再打開。
2.寬度優(yōu)先
寬度優(yōu)先比較好理解,就是搜索引擎蜘蛛先把整個(gè)頁面的鏈接全部抓取一次,然后在抓取下一個(gè)頁面的全部鏈接。所以網(wǎng)頁的層度不能太多,否則會(huì)導(dǎo)致收錄難,因?yàn)樗恋K了搜索引擎蜘蛛的寬度優(yōu)先策略。
3.權(quán)重優(yōu)先
寬度優(yōu)先比深度優(yōu)先,只能說各有各的好處,而且蜘蛛都是兩種抓取策略一起用,也就是深度優(yōu)先+寬度優(yōu)先, 只不過在使用兩種策略抓取時(shí),會(huì)參照鏈接的權(quán)重,如果說這條連接的權(quán)重還不錯(cuò),那么采用前者,權(quán)重低,那么采用寬度優(yōu)先!
那么蜘蛛怎樣知道鏈接的權(quán)重呢?有2個(gè)因素,層次的多與少、外鏈多少與質(zhì)量。
重訪抓取
比如今天蜘蛛來抓取了的網(wǎng)頁,如果明天網(wǎng)頁加了新的內(nèi)容,那么蜘蛛會(huì)來抓取新的內(nèi)容!重訪抓取分為全部重訪:指蜘蛛上次抓取的鏈接,然后在這一個(gè)月的某一天,全部重新去訪問抓取一次!單個(gè)重訪:針對(duì)某個(gè)頁面更新的頻率比較快比較穩(wěn)定的頁面,如果說有個(gè)頁面1個(gè)月不更新。那么蜘蛛第三天就不來了,會(huì)隔段時(shí)間,比如隔個(gè)半年,或等全部重訪時(shí)再來。
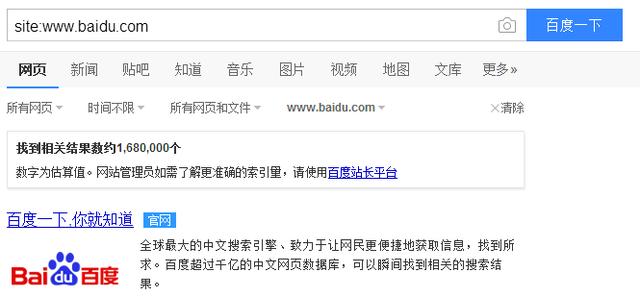
PS:檢查網(wǎng)站是否收錄的方法:
1.在百度搜索框中輸入,site:網(wǎng)站網(wǎng)址
2.在站長工具當(dāng)中輸入域名,進(jìn)行查詢
本文由今科科技用戶上傳并發(fā)布,今科科技僅提供信息發(fā)布平臺(tái)。文章代表作者個(gè)人觀點(diǎn),不代表今科科技立場。未經(jīng)作者許可,不得轉(zhuǎn)載,有涉嫌抄襲的內(nèi)容,請(qǐng)通過 反饋中心 進(jìn)行舉報(bào)。
售前咨詢:0760-2332 0168
售后客服:400 830 7686
1998~2024,今科26年專注于企業(yè)信息化服務(wù)
立 即 注 冊(cè) / 咨 詢
上 線 您 的 網(wǎng) 站 !
